
사용한 기술 스택들:
![]()
LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch (github.com)
GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
MNIST model trained using various models, implemented in PyTorch - GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
github.com
오늘은 저번 포스팅에 이어서 손글씨 분류기를 만들어 보겠다.
저번엔 인공신경망(ANN)으로 MNIST 데이터셋을 분류해 보았다. 2개의 은닉층(Hidden layer)만으로도 상당한 성능을 보여줬지만, 97.6%라는 정확도에 그쳤다. 여기서 은닉층을 더 더하는 것보다 새로운 모델을 적용해보자. CNN(Convolutional Neural Network)를 사용한 LeNet-5이다!
이 포스팅은 MNIST데이터셋의 대한 두 번째 포스팅이기 때문에 첫 번째 포스트를 보고 오는 걸 추천한다.
https://limepencil.tistory.com/3
MNIST 데이터셋 활용해서 간단한 딥러닝으로 손글씨 분류기 만들기
사용한 기술 스택들: LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch (github.com) GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented..
limepencil.tistory.com
LeNet-5이란?
LeNet은 Yann LeCun이라는 프랑스 컴퓨터 사이언티스트가 1998년에 발표한 논문에서 나온 모델이다.
논문 링크: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
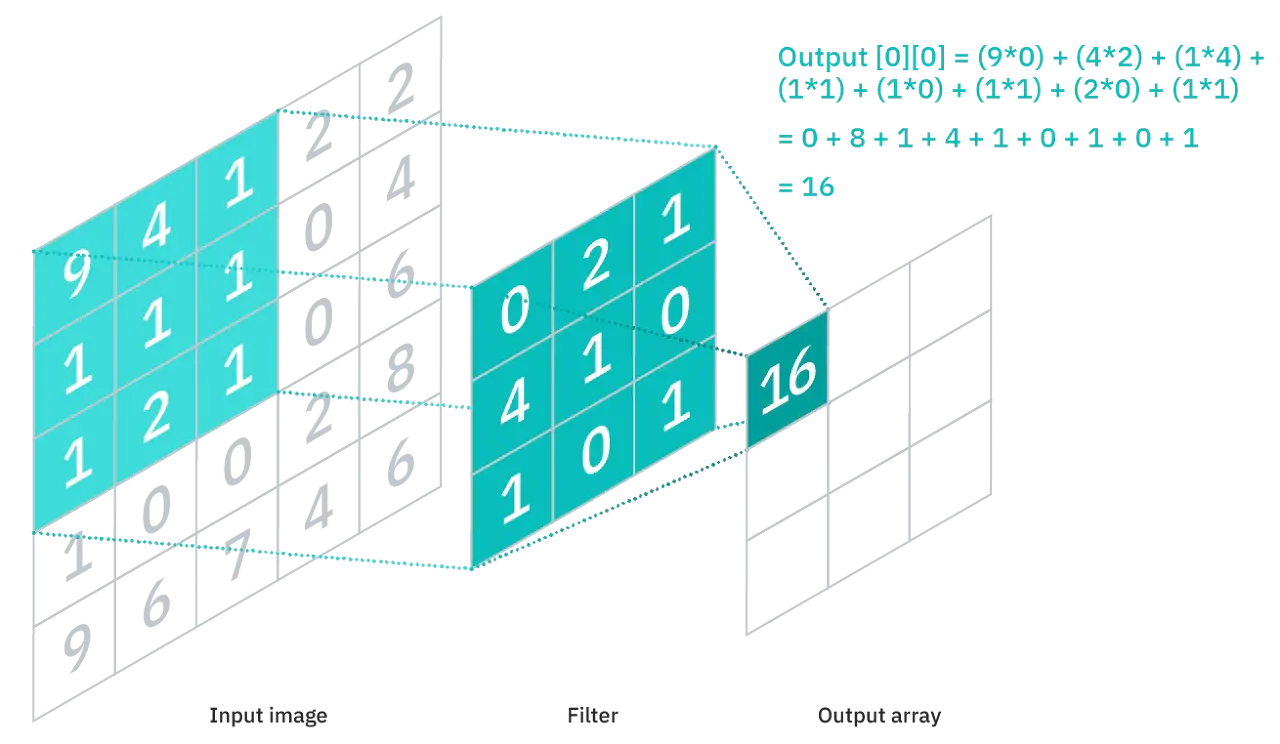
손글씨와 프린트한 글씨를 분류할 때 1%의 에러를 보였다고 한다. 저번 포스팅은 2.4%의 정확도였는데 상당한 결과이다. 이 높은 정확도를 가능하게 한 것은 모두 다 CNN 덕분이다. CNN은 다른 포스팅으로 설명하기로 하고, 이미지 같은 것을 훈련시킬 때 적합한 신경망 구조라고 생각하면 된다. 이 논문이 나왔을 쯤에는 CNN이 그렇게 유명하지 않았지만, GPU를 통한 병렬 계산이 가능해지면서 CNN이 떠오르기 시작했다. 이 모델로 미국 우편번호 인식도 잘할 수 있었다고 한다. (Backpropagation Applied to Handwritten Zip Code Recognition | Neural Computation | MIT Press)
코드
코드 구조는 이전 포스팅과 거의 비슷하다. model class만 교체해주는 것이기 때문에 저장, 모델 로드, 평가, 그래프는 이전 포스팅을 참고하도록 하자.
https://limepencil.tistory.com/3
MNIST 데이터셋 활용해서 간단한 딥러닝으로 손글씨 분류기 만들기
사용한 기술 스택들: LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch (github.com) GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented..
limepencil.tistory.com
DOWNLOAD_ROOT = os.path.join(os.pardir,"MNIST_data")
dataset_1 = datasets.MNIST(root=DOWNLOAD_ROOT,train=True,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()]),download=True)
dataset_2 = datasets.MNIST(root=DOWNLOAD_ROOT,train=False,transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()]),download=True)먼저, 데이터셋을 불러오는 코드가 조금 바뀌었다. LeNet-5는 32x32 사이즈의 이미지를 input으로 받기 때문에 28x28인 MNIST데이터셋을 transforms.Resize((32,32))로 바꾸어야 해 줄 필요가 있다. transforms.Compose를 사용하면 다양한 transforms를 묶어서 쓸 수 있다.
while epoch < EPOCHS:
cost = 0
for image, label in dataset_1_loader:
optimizer.zero_grad()
predicted = model.forward(image)
loss = loss_function(predicted,label)
loss.backward()
optimizer.step()
cost+=loss
with torch.no_grad():
total = 0
correct = 0
for image, label in dataset_2_loader:
out = model(image)
_,predict = torch.max(out.data, 1)
total += label.size(0)
correct += (predict==label).sum()
average_cost = cost/TOTAL_BATCH
accuracy = 100*correct/total
loss_list.append(average_cost.detach().numpy())
accuracy_list.append(accuracy)
epoch+=1
print("epoch : {} | loss : {:.6f}" .format(epoch, average_cost))
print("Accuracy : {:.2f}".format(accuracy))
print("---------------------")
if epoch%5 ==0:
torch.save({"epoch":epoch,"loss list":loss_list,"accuracy list":accuracy_list,"model":model.state_dict(),"optimizer":optimizer.state_dict()},PATH)위에서도 그냥 dataset_1_loader에서 받아온 image를 바로 넣어주도록 하자. 그전 인공신경망과는 다르게 이 모델은 이미지를 바로 input에 받기 때문에 flatten 시켜줄 필요가 없다.
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()
self.c1 = nn.Conv2d(1,6,5)
self.maxpool1 = nn.MaxPool2d(2)
self.c2 = nn.Conv2d(6,16,5)
self.maxpool2 = nn.MaxPool2d(2)
self.c3 = nn.Conv2d(16,120,5)
self.n1 = nn.Linear(120,84)
self.relu = nn.ReLU()
self.n2 = nn.Linear(84,10)
def forward(self,x):
x = self.c1(x)
x = self.relu(x)
x = self.maxpool1(x)
x = self.c2(x)
x = self.relu(x)
x = self.maxpool2(x)
x = self.c3(x)
x = self.relu(x)
x = torch.flatten(x,1)
x = self.n1(x)
x = self.relu(x)
x = self.n2(x)
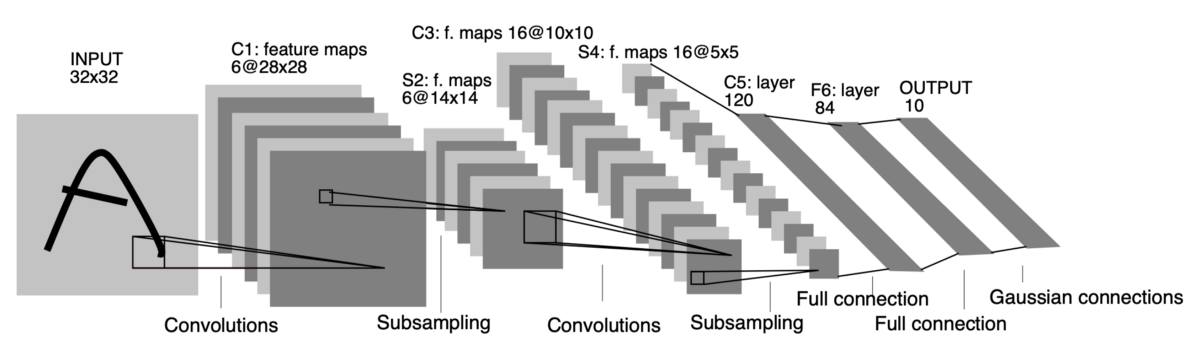
return x이 코드를 보자. 밑에 있는 사진은 이 모델의 구조이다. 논문에서는 tanh를 활성 함수로 사용하였지만 여기서는 reLU를 사용한다. 만약에 논문을 똑같이 따라 하고 싶으면 nn.tanh()를 해주자. 3개의 CNN layer을 지나고 그 중간중간에는 maxpool로 크기를 반으로 줄인다. 그다음에는 2개의 은닉 신경층이 있다.
결과
나온 결과는 상당히 놀랍다. 인공신경망은 97.6%의 정확도를 보여줬던 것에 비해 LeNet-5은 98.8프로라는 정확도를 보여줬다. 5배의 시간이 걸리긴 했지만(25분 100 epoch) 상당한 결과를 보여준다는 걸 알 수 있다.


다음 포스팅에서는 더욱더 이 모델을 발전시켜보겠다. Hyperparameter tuning이나 새로운 모델을 가지고 올 생각이다.
전체 코드:
MNIST/train.ipynb at master · LimePencil/MNIST (github.com)
GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
MNIST model trained using various models, implemented in PyTorch - GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
github.com
'Machine Learning > MNIST' 카테고리의 다른 글
| MNIST 데이터셋 활용해서 간단한 딥러닝으로 손글씨 분류기 만들기: MNIST-1 (0) | 2022.03.19 |
|---|