
사용한 기술 스택들:
![]()
LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch (github.com)
GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
MNIST model trained using various models, implemented in PyTorch - GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
github.com
오늘은 MNIST라는 데이터셋을 사용해서 손글씨 분류기를 만들어 보려 한다

MNIST는 NIST라는 데이터셋을 가공하여 0~9의 인간의 손글씨를 28*28 grayscale 이미지로 모아논 것이다. 인터넷에 다양한 곳에서 받을 수 있지만, 이 글에서는 PyTorch를 사용할 것이기 때문에 Torchvision이라는 PyTorch와 같이 있는 패키지를 사용해서 데이터셋을 받을 것이다. Python만 사용하여도 좋지만 Jupyter notebook을 사용하면 더욱더 편하다.
코드
먼저, PyTorch와 Torchvision 패키지들을 설치했다는 가정하에 시작하겠다.
필요한 라이브러리를 먼저 불러온다.
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torchvision
import numpy as np
from torchvision import transforms
import os
from torchinfo import summary
이 두줄의 코드를 사용하면 Nvidia 그래픽 개열의 그래픽 카드를 사용해서 더 빠르게 훈련시킬 수 있다. cuda는 그래픽 카드에 있는 쿠다 코어이다 (병렬 연산을 지원한다고 한다). NVIDIA Developer Program Membership Required | NVIDIA Developer 여기에서 cuDNN을 받고 PyTorch에서 cuda를 지원하는 패키지를 다운로드하도록 하자. Nvidia 그래픽 카드가 없다면 CPU를 사용하자. 맥도 그래픽 카드 지원해주세요.
USE_CUDA = torch.cuda.is_available()
device = torch.device("cuda" if USE_CUDA else "cpu")
DOWNLOAD_ROOT라는 변수에 MNIST 데이터셋을 받을 곳을 지정하자.
그리고 torchvision에서 datasets.MNIST라는 class로 데이터를 받는다.
2번 dataset은 train을 False로 하자 (test용 dataset).
transform을 transforms.ToTensor()로 설정해서 이미지를 텐서로 변환하자.
# 부모 폴더에 있는 MNIST_data라는 폴더에 저장한다는 뜻
DOWNLOAD_ROOT = os.path.join(os.pardir,"MNIST_data")
dataset_1 = datasets.MNIST(root=DOWNLOAD_ROOT,train=True,transform=transforms.ToTensor(),download=True)
dataset_2 = datasets.MNIST(root=DOWNLOAD_ROOT,train=False,transform=transforms.ToTensor(),download=True)
아까 torch.utils.data 에서 불러온 DataLoader 클래스로 데이터셋을 불러오는 loader을 생성하였다. drop_last 인자는 맨 마지막 batch에서 남아있는 데이터가 batch_size보다 작을 때 drop 할 건지 아니면 그대로 받을 건지 설정하는 것이다.
BATCH_SIZE = 128
loader_1 = DataLoader(dataset_1, batch_size=BATCH_SIZE, shuffle=True,drop_last=True)
loader_2 = DataLoader(dataset_2, batch_size=BATCH_SIZE, shuffle=True,drop_last=True)
딥 러닝 모델
여기에서는 간단한 딥 러닝 model을 정의한다. 28x28의 이미지를 받아서 flatten 해준 tensor을 100개의 neuron이 있는 2개의 layer에 보내고 마지막에 10개 (0-9 숫자 분류)가 나오게 model을 정의하자. 네트워크 중간에는 ReLU activation function을 사용한다.
class n_net(nn.Module):
def __init__(self):
super(n_net,self).__init__()
self.n1 = nn.Linear(784,100)
self.relu = nn.ReLU()
self.n2 = nn.Linear(100,100)
self.n3 = nn.Linear(100,10)
def forward(self,x):
x1 = self.n1(x)
x2 = self.relu(x1)
x3 = self.n2(x2)
x4 = self.relu(x3)
x5 = self.n3(x4)
return x5
TylerYep/torchinfo: View model summaries in PyTorch! (github.com)
torchinfo라는 라이브러리를 받으면 model의 summary를 볼 수 있는데, 상당히 유용하다.
summary(model,input_size=(BATCH_SIZE,784))결과:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
n_net -- --
├─Linear: 1-1 [128, 100] 78,500
├─ReLU: 1-2 [128, 100] --
├─Linear: 1-3 [128, 100] 10,100
├─ReLU: 1-4 [128, 100] --
├─Linear: 1-5 [128, 10] 1,010
==========================================================================================
Total params: 89,610
Trainable params: 89,610
Non-trainable params: 0
Total mult-adds (M): 11.47
==========================================================================================
Input size (MB): 0.40
Forward/backward pass size (MB): 0.22
Params size (MB): 0.36
Estimated Total Size (MB): 0.97
==========================================================================================
여기서는 다양한 변수들을 선언해주자. LOAD는 그전에 저장해놓은 model을 불러올 건지 결정하는 변수이다. SEED는 똑같은 시드를 가졌으면 여러 번 훈련을 시켜도 같은 결과가 나오게 해 준다. 손실 함수는 CrossEntropyLoss로 정하고, SGD(surface gradient descent)로 최적화를 한다. 각 epoch당 생기는 loss와 accuracy를 loss_list와 accuracy_list에다가 저장하자.
LOAD = False
LEARNING_RATE = 0.01
SEED = 7777
torch.manual_seed(SEED)
if device == 'cuda':
torch.cuda.manual_seed_all(SEED)
model = n_net()
model.zero_grad()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=LEARNING_RATE)
TOTAL_BATCH = len(loader_1)
EPOCHS = 100
loss_list = []
accuracy_list = []
epoch = 0
모델 저장
SAVE_INTERVAL 마다 model을 저장해 줄 것이고 LOAD == True 이면 torch.load를 이용해서 불러온다. 현재는 Save라는 폴더에 pretrained_model을 저장하기에, Saves라는 폴더를 먼저 만들어놔야 그곳에 저장할 수 있다.
PATH = os.path.join("Saves","pretrained_model.pt")
SAVE_INTERVAL = 5
if LOAD:
check = torch.load(PATH)
model.load_state_dict(check["model"])
epoch = check["epoch"]
accuracy_list = check["accuracy list"]
loss_list = check["loss list"]
optimizer.load_state_dict(check["optimizer"])
모델 training/evaluation
전체 코드이다. 지금부터 하나하나 설명하겠다
while epoch < EPOCHS:
cost = 0
for image, label in loader_1:
image = image.reshape(BATCH_SIZE,784)
optimizer.zero_grad()
predicted = model.forward(image)
loss = loss_function(predicted,label)
loss.backward()
optimizer.step()
cost+=loss
with torch.no_grad():
total = 0
correct = 0
for image, label in loader_2:
image = image.reshape(BATCH_SIZE,784)
out = model(image)
_,predict = torch.max(out.data, 1)
total += label.size(0)
correct += (predict==label).sum()
average_cost = cost/TOTAL_BATCH
accuracy = 100*correct/total
loss_list.append(average_cost.detach().numpy())
accuracy_list.append(accuracy)
epoch+=1
print("epoch : {} | loss : {:.6f}" .format(epoch, average_cost))
print("Accuracy : {:.2f}".format(accuracy))
print("---------------------")
if epoch%5 ==0:
torch.save({"epoch":epoch,"loss list":loss_list,"accuracy list":accuracy_list,"model":model.state_dict(),"optimizer":optimizer.state_dict()},PATH)
Training:
여기서는 순전파(forward propagation)를 한다. reshape을 사용해서 28x28을 784짜리 배열로 바꿔준다. optimizer.zero_grad()을 써서 gradient를 초기화해주고, model에 batch를 넣는다. 나온 결과에 loss를 계산해주고, loss.backward()으로 계산한 값을 optimizer.step() 함수로 모델을 업데이트를 한다(back propagation). 마지막에 cost라는 변수에 loss값을 저장하여 총 손실 값이 얼마인지 저장한다.
cost = 0
for image, label in loader_1:
image = image.reshape(BATCH_SIZE,784)
optimizer.zero_grad()
predicted = model.forward(image)
loss = loss_function(predicted,label)
loss.backward()
optimizer.step()
cost+=loss
Evaluation:
여기서는 얼마나 model이 정확한지 평가를 한다. total에는 evaluation에 사용한 이미지가 몇 개인지 저장하고 correct에는 몇 개가 맞았는지 저장한다. with torch.no_grad()를 사용함으로써 모델이 평가 중에 업데이트가 되는 걸 방지한다.
with torch.no_grad():
total = 0
correct = 0
for image, label in loader_2:
image = image.reshape(BATCH_SIZE,784)
out = model(image)
_,predict = torch.max(out.data, 1)
total += label.size(0)
correct += (predict==label).sum()
한 epoch가 끝이 나면, 평균 cost와 accuracy를 계산하고 저장한다. 그리고 SAVE_INTERVAL 마다 모델을 torch.save()로 저장을 한다.
average_cost = cost/TOTAL_BATCH
accuracy = 100*correct/total
loss_list.append(average_cost.detach().numpy())
accuracy_list.append(accuracy)
epoch+=1
print("epoch : {} | loss : {:.6f}" .format(epoch, average_cost))
print("Accuracy : {:.2f}".format(accuracy))
print("---------------------")
if epoch%SAVE_INTERVAL ==0:
torch.save({"epoch":epoch,"loss list":loss_list,"accuracy list":accuracy_list,"model":model.state_dict(),"optimizer":optimizer.state_dict()},PATH)
그래프 그리기(Plotting)
matplotlib으로 그래프를 그려서 데이터를 시각화해보자.
아래의 코드는 손실 그래프와 정확도 그래프를 그린 후 graph.png라는 이름으로 저장을 한다. 그래프를 보면 97.6%의 정확도를 기록하고 있는 걸 볼 수 있다.
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.text(EPOCHS-1-15,loss_list[-1]+0.1,'({:.3f})'.format(loss_list[-1]))
plt.plot(np.arange(0,EPOCHS),loss_list)
plt.subplot(1,2,2)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.text(EPOCHS-1-15,accuracy_list[-1]-3,'({:.1f}%)'.format(accuracy_list[-1]))
plt.plot(np.arange(0,EPOCHS), accuracy_list)
plt.savefig('graph.png',facecolor = 'w')
plt.show()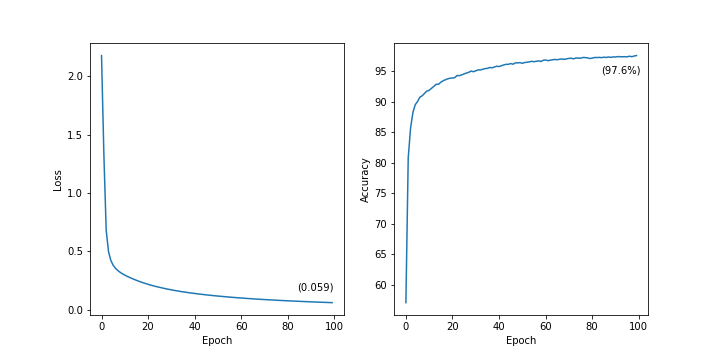
이 코드는 cols, rows 만큼의 크기의 이미지 몇 개를 뽑아서 예상한(label)과 실제 이미지(actual)가 어떠한지 비교할 수 있게 해 준다. 현재는 5,2 이기 때문에 10개의 예시를 보여준다. 마찬가지로 output.png에 저장한다.
figure = plt.figure(figsize=(10, 5))
cols, rows = 5, 2
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(dataset_2), size=(1,)).item()
img, label = dataset_2[sample_idx]
image = img.reshape(1,784)
figure.add_subplot(rows, cols, i)
out = model(image)
_,predict = torch.max(out.data, 1)
plt.title("label: {} actual: {}".format(label,predict.item()))
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.savefig('output.png',facecolor = 'w')
plt.show()
결론
간단한 딥 러닝 모델을 만들고 훈련시켰지만 100 epoch 만에 97.6%라는 정확도를 보여줘서 놀라웠다(Macbook M1에서 5분만 훈련한 결과이다!). hyperparameter tuning이나 더 나은 모델을 사용하면 정확도가 더 올라갈 것으로 예상된다.
다음 포스팅은 LeNet-5를 사용한 CNN으로 MNIST데이터셋 분류를 해볼 것이다.
오늘 사용한 코드 링크는 여기에 있다: MNIST/train.ipynb at master · LimePencil/MNIST (github.com)
GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
MNIST model trained using various models, implemented in PyTorch - GitHub - LimePencil/MNIST: MNIST model trained using various models, implemented in PyTorch
github.com
'Machine Learning > MNIST' 카테고리의 다른 글
| LeNet-5으로 더욱더 정확한 손글씨 분류기 만들기: MNIST-2 (0) | 2022.03.23 |
|---|