![[논문 리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb0WvzC%2FbtsOB6LLHno%2FAAAAAAAAAAAAAAAAAAAAAI08pt3u7RqCBMYyh4MQS4MMFO33sZrKKZ82emU4aAO5%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3Da%252FHTJSugygTDppnUVPBrrvW9DmY%253D)
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Introduction
Self-attention 기반의 구조인 Transformers는 원래 자연어 처리(NLP)를 위해 개발되었습니다. 반면, 컴퓨터 비전(CV) 작업에서는 오랜 시간 동안 convolutional neural networks (CNNs)가 지배적이었습니다.
처음에는 self-attention과 CNN을 통합하려는 시도가 좋지 않은 결과를 보였습니다. Vision Transformer (ViT)는 이미지를 패치(patch)로 나누고 (transformer의 토큰(token)과 유사)각 패치를 선형으로 embedding하여 이를 표준 Transformer에 입력하는 새로운 방식을 제시했습니다.
ViT의 문제점
- ImageNet과 같은 중간 크기의 데이터셋에서 성능이 좋지 않음
- CNN이 가진 inductive biases가 부족:
- Translation equivariance: 입력이 이동하면 출력도 일관되게 이동
- Locality: 공간적으로 인접한 특징을 강조
이런 문제점들은 ImageNet에 더 많은 데이터셋을 추가하여 학습을 하면 더 좋을 성능을 낼 수 있습니다.
Methodology
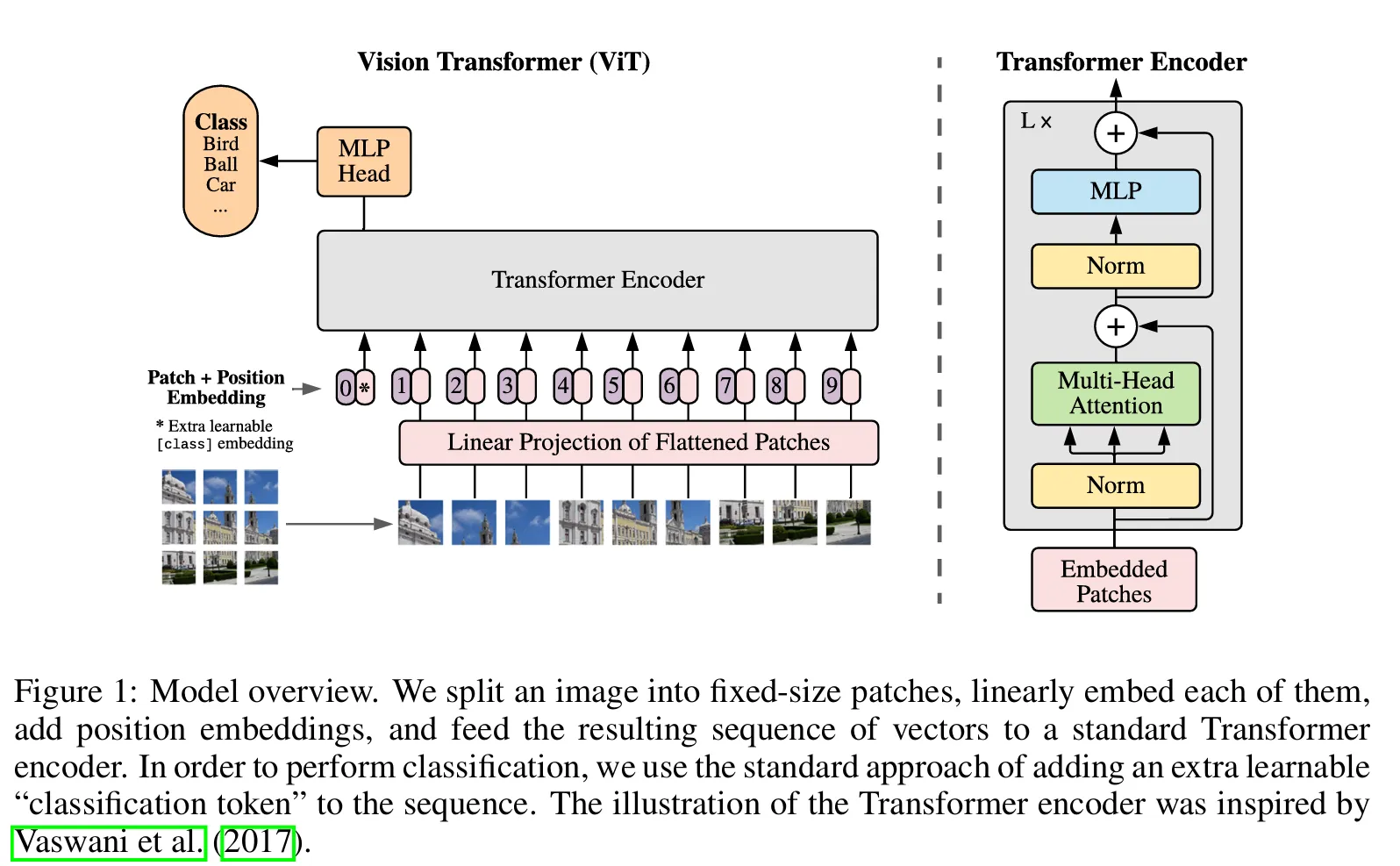
- Patch Embedding:
- 입력 이미지를 겹치지 않는 고정 크기 패치로 나눔
- 각 패치를 벡터로 선형 투영(linear projection)
- $\mathbf{x}_p \in \mathbb{R}^{H \times W \times C} \rightarrow \mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$, 여기서 $N$ 은 패치의 수
- 각 패치는 일정한 잠재 차원 $D$ 로 투영
- Class Token:
- 학습 가능한 분류 토큰 ([CLS])이 입력 시퀀스 앞에 추가됨
- BERT와 유사하게 종합적인 표현을 함
- Positional Embedding:
- 공간 순서를 유지하기 위해 1D 학습 가능한 positional embeddings 추가
- 2D positional embeddings는 추가적인 이점이 제한적
- Transformer Encoder:
- Multi-headed Self-Attention (MSA)과 MLP 블록이 번갈아 구성
- Residual connections와 LayerNorm 포함
- Classification Head:
- 최종 [CLS] 토큰 표현을 MLP를 통해 분류
Architecture
$$
z_0 = [x_{\text{class}}; x_p^1 E; x_p^2 E; \cdots; x_p^N E] + E_{\text{pos}} \tag{1}
$$
$$
E \in \mathbb{R}^{(P^2 \cdot C) \times D}, \quad E_{\text{pos}} \in \mathbb{R}^{(N+1) \times D}
$$
$$
z_{\ell}' = \mathrm{MSA}(\mathrm{LN}(z_{\ell - 1})) + z_{\ell - 1}, \quad \ell = 1, \ldots, L \tag{2}
$$
$$
z_{\ell} = \mathrm{MLP}(\mathrm{LN}(z_{\ell}')) + z_{\ell}', \quad \ell = 1, \ldots, L \tag{3}
$$
$$
y = \mathrm{LN}(z_L^0) \tag{4}
$$
ViT의 Inductive Biases
ViT는 CNN과 같은 명시적인 inductive biases가 없지만, 로컬 및 글로벌 특징을 모두 학습합니다.
- MSA는 장거리 의존성(long-range dependencies)을 포착
- MLP 층은 로컬 상호작용(local interactions)을 촉진
Hybrid ViT-CNN 아키텍처
낮은 해상도로 사전 학습된(pretrained) ViT는 고해상도 입력으로 Fine-tuning 가능합니다.
- 패치 크기는 고정되고, 시퀀스 길이가 증가
- 2D 보간(interpolation)으로 학습된 positional embeddings를 새 입력 해상도에 맞춤
Experimental Results
Experimental Setup
- 사전 학습 데이터셋:
- ImageNet (1.3M 이미지)
- ImageNet-21k (14M 이미지)
- JFT-300M (303M 이미지)
- 평가 벤치마크:
- ImageNet, CIFAR-10/100, VTAB (19개 작업), Oxford Pets, Flowers-102
- 모델 변형(variants):
- ViT-Base, ViT-Large, ViT-Huge
- 비교 기준:
- ResNet (BiT), Noisy Student (EfficientNet)
Key Findings
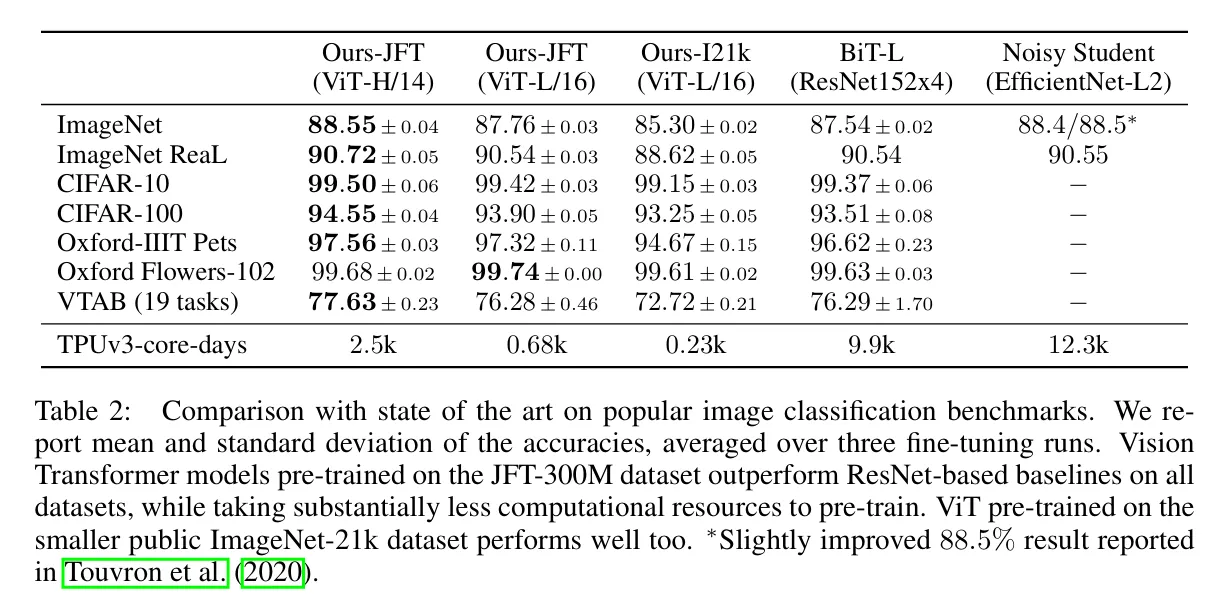
- 성능:
- 큰 데이터셋에서 사전 학습된 ViT는 CNN과 동등하거나 더 우수한 성능을 보임
- ViT-H/14의 성능:
- ImageNet: 88.55%
- CIFAR-100: 94.55%
- VTAB: 77.63%
- 계산 효율성(Compute Efficiency):
- ViT-H/14는 ResNet 기반 모델보다 적은 계산 자원(2.5k vs. 9.9k TPUv3-core-days)을 사용하며 더 좋은 성능을 보임
- 데이터 요구 사항:
- ViT는 작은 데이터셋에서 CNN보다 성능이 낮음
- 큰 규모의 데이터로 성능이 현저히 향상됨
- 확장성(Scalability):
- 모델의 깊이, 너비 또는 패치 크기를 늘리면 성능이 향상됨
- 매우 큰 모델에서도 성능 포화(saturation) 징후가 없음
- Few-Shot Learning:
- ViT는 대규모 사전 학습의 혜택으로 Few-shot 분류에서 강력한 성능을 보임
- Self-Supervised Learning (Preliminary Results):
- Masked patch prediction은 ImageNet 정확도를 약 2% 향상
- 여전히 supervised 사전 학습에 비해 성능이 낮음
- Attention 시각화:
- ViT는 로컬 및 글로벌 attention 패턴을 모두 나타냄
- Positional embeddings는 명시적 구조가 없어도 공간적 토폴로지를 포착
Conclusion
Vision Transformers는 이미지 특유의 inductive biases가 없지만, 큰 데이터셋에서 훈련될 경우 CNN과 비교하여 우수한 성능을 달성하고 있습니다. 확장성과 계산 효율성이 뛰어나며 Few-shot 및 Self-supervised 학습에서도 효과적입니다. Local and global dependency을 모델링할 수 있어 향후 CV문제들에 유망한 아키텍쳐입니다.