![[논문 리뷰] Are GAN generated images easy to detect? A critical analysis of the state-of-the-art](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fem6lQD%2FbtslS2CmEzT%2FAa4ThKUkpWsorCbTVZnsFK%2Fimg.png)
AI CONNECT에서 진행하는 Fake or Real: AI 생성 이미지 판별 경진대회를 참가하기 위해 여러 가지 논문을 뒤적이던 중에 괜찮은 논문이 있어서 리뷰를 해보려고 한다.
https://arxiv.org/abs/2104.02617
Are GAN generated images easy to detect? A critical analysis of the state-of-the-art
The advent of deep learning has brought a significant improvement in the quality of generated media. However, with the increased level of photorealism, synthetic media are becoming hardly distinguishable from real ones, raising serious concerns about the s
arxiv.org
Abstract & Introduction
이 논문에서는 생성 이미지를 판별하는 SOTA method를 분석하고 비교해 본다. 어떤 factor이 detection에 큰 도움을 주는지, 그리고 현재의 generative architecture들에 이 방법이 얼마나 효용이 있는지를 다뤘다.

GAN은 특별한 trace를 생성된 이미지에 남기는데, 이를 이용하여 detection이 가능하다. 기술이 발전함으로써 이것이 줄어들겠지만, 이 trace는 생성 모델의 구조 그 자체와 관계가 있다. 각각의 GAN architecture마다 특정한 artificial fingerprint가 있다. 이를 Fourier transform으로 찾을 수 있는데 (위에 있는 파란색 사진) 데이터에 따라서도 이 fingerprint가 바뀌기 때문에 다른 방법을 찾아야 한다.
요즘에는 deep neural network만을 사용하여 detection을 하기도 하는데, 그렇다면 이 task자체가 쉬워 보이나 사실 상당히 어렵다. 원본의 이미지를 가지고 있을 때는 이런 trace들을 찾기가 쉽지만 compression과 distortion이 흔한 인터넷상에서는 이런 흔적들이 사라지기 때문에 더 challenging 해진다. 또한, 계속 새로운 생성모델이 만들어지고, 이에 대한 데이터를 구하기가 어려워지고 있다.
State-of-the-art-methods
이 논문에서는 현재 SOTA를 3가지로 나누어서 설명하고 있는데
- Learning spatial domain features
- 예전에 사용한 방법은 이미지의 기원을 찾는 방법이나 위에서 말했던 fingerprint를 찾는 방법이다.
- GAN의 특성을 exploit 하여 색의 intensity value의 한계, saturated or underexpose region 존재 유무, color band 간의 상관관계 등등을 이용하여 판단을 한다
- Learning frequency domain features
- Fourier domain에 있는 trace들을 활용하여 upsampling시에 남은 흔적이나, 여러 가지 achitiecture만의 흔적을 찾는다
- Fourier spectra를 활용한 CNN-based classifier 활용
- 생성 이미지와 진짜 이미지와의 energy spectral distribution을 비교
- Learning feature that generalize
- 위에 제기된 방법들은 training data가 test data와 같을 때 유효하지만 generalization이 약하다. 이를 위해 few-shot learning 방법들이 제시되었다(autoencoder-based)
- Augmentation(gaussian blurring)을 활용하여, 더 generalize 한 feature을 학습하도록 하는 방법이 있다. 이를 쓰면 하나의 GAN architecture만으로도 학습을 하여도 높은 generalization 성능을 보여주었다.
- fully convolutional patch-based classifier을 활용하여 patch에 집중함으로써 더 좋은 성능을 보여줄 수 있다
Datasets
이 실험에서 사용한 데이터는 36만 장의 LSUN 데이터셋에서 가져온 진짜 이미지와 각각 다른 cateogry에서 학습한 20개의 ProGAN 모델을 사용하여 36만 장의 생성 이미지를 만들었다. Generalization을 테스트하기 위해서 testing phase에서는 training때 보지 못한 low-resolution(256x256)과 high-resolution(1024x1024) 이미지가 섞인 7개의 다른 GAN 모델에서 생성한 이미지를 사용하였다. 또한 ImageNet, COCO, RAISE 데이터를 진짜 이미지로 사용하였다.
Experimental Results
이 논문에서는 다양한 detector(Xception, SRNet, Spec, M-Gb, Co-Net, Wang2020, PatchForensics)를 시험을 했다. 논문에서는 SRNet이 noise residual에 관련된 feature들을 보존하는 데다가 downsampling이 없어서 좋다고 한다. Generalization을 테스트한 실험에서는 AUC는 높지만 accuracy 같은 경우에는 좀 낮은 부분이 있다고 한다. 또한 compression을 진행했을 때 augmentation을 사용해서 학습한 모델이 좋은 결과를 보여주고 있다고 한다. 어떤 상황에서라도 2x downsampling을 하면 성능이 낮아진다. 이는 GAN의 artifact를 소실시켜 주는 역할을 하기 때문이다.
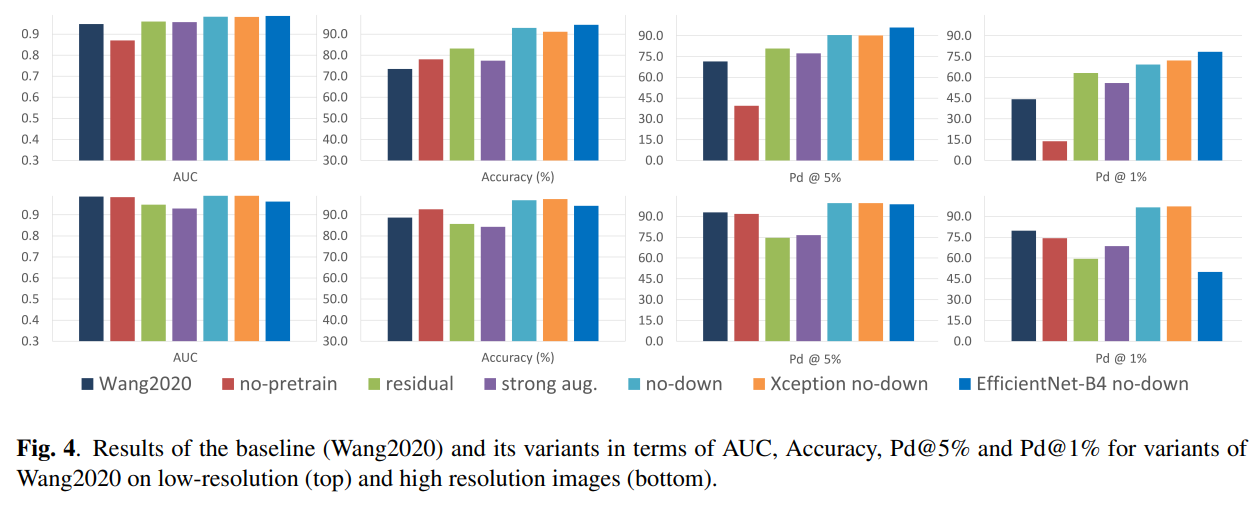
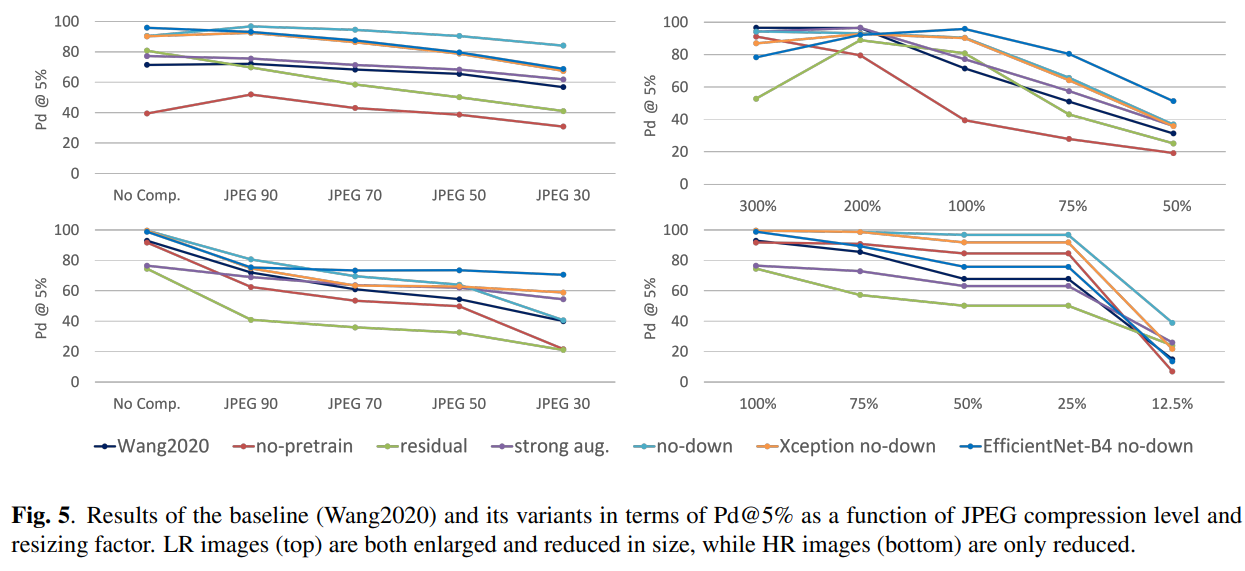
또한, contributing factor을 찾기 위해 실행한 실험에서는 다음과 같이 variable을 바꾸어 보면서 진행했는데 no downsampling이 큰 역할을 한다는 것을 알 수 있다. 논문에서는 15%의 accuracy와 14%의 Pd@5%의 증가를 가져왔다고 한다.
Conclusion
- 아직 GAN image detection을 하기 위한 reliable tool은 없다
- downsampling을 하지 않는 것이 성능을 올려준다
'논문 리뷰 > Computer Vision' 카테고리의 다른 글
| [논문 리뷰] On the detection of synthetic images generated by diffusion models (0) | 2023.07.06 |
|---|